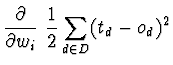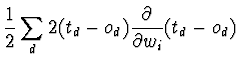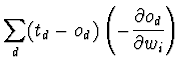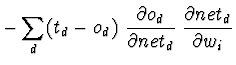|
Ao contrário de um neurónio individual, uma rede neuronal de muilti-camadas tem a capacidade de exprimir uma enorme variedade de superfícies não lineares. Este tipo de RN permite resolver problemas de complexidade elevada, mas em contrapartida são exigidas RN complexas. Naturalmente, que o tempo de treino da RN aumentará com a sua complexidade e por vezes poder-se-á tornar insuportável treinar uma RN como desejado.
A figura 1 representa uma RN multi-camadas:
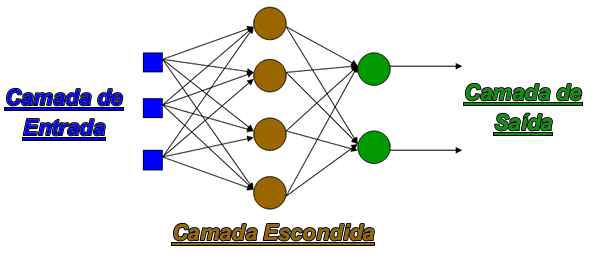
Fig. 1: Rede Neuronal Multi-Camadas
Cada Rede Neuronal deste tipo possui:
- 1 camada de entrada
- 1 ou mais camadas escondidas
- 1 camada de saída
Quanto maior fôr o número de camadas escondidas na RN, maior é a sua capacidade de resolução de problemas.
A tabela 1 clarifica esta relação. Superfície de Decisão | Esquema Neuronal | Exemplo1 : Um neurónio | 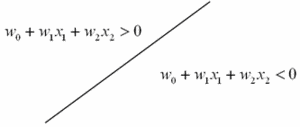 | 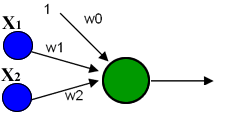 | Exemplo2: RN - uma camada escondida (RN1CE) | 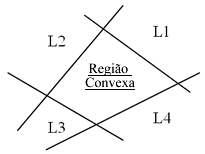 | 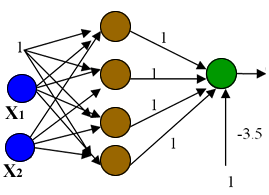 | Exemplo3: RN - duas camadas escondidas |  | 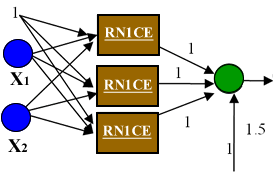 |
Tabela 1: Relação entre o tipo de RN e a respectiva superfície de decisão.
Tal como visto anteriormente, com um neurónio (ex. 1) apenas é possivel separar exemplos linearmente. No entanto quando se adiciona uma camada escondida (ex. 2) à RN é possivel realizar um região convexa onde cada nó escondido é responsável por uma das fronteiras da região. Uma rede neuronal com duas camadas escondidas (ex. 3) realiza a reunião de três regiões convexas. Cada caixa a castanho representa uma rede neuronal com uma cada escondida (RN1CE) que realiza uma região convexa. Este último exemplo é demonstrativo do potencial que várias RN interligadas podem representar.
Para as RN Multi-camada não se vai poder usar a unidade linear nem o perceptrão. Várias camadas de unidades lineares em cascata apenas produzirão funções lineares e a saída do perceptrão não é indiferenciável e como tal não se pode aplicar a descida do gradiente. Neste tipo de redes, cujo objectivo é conseguir representar funções complexas não lineares, é necessário uma unidade cuja saída seja uma função não linear e diferenciável das entradas.
A unidade sigmóide apresentada na figura 2 preenche estes requisitos.
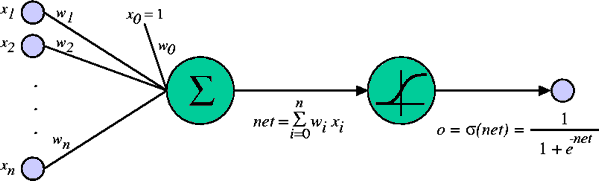
Fig. 2: Unidade Sigmóide com threshold
onde 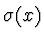 é a função sigmóide é a função sigmóide 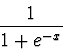
Variações à função sigmóide poderão ser introduzidas pela seguinte fórmula:
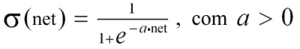
A influencia da variável a pode ser entendida interpretando o gráfico da figura 3.
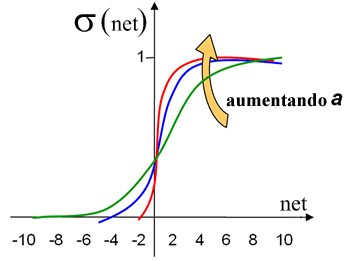
Figura 3: Variações do gráfico da função sigmóide em função de a
Os valores de saída situam-se no intervalo [0,1] e aumentam monotonamente com a entrada (ver figura 3).
É possível derivar regras da descida do gradiente para treinar:
- uma unidade sigmóide
- um rede multi-camadas constituída por unidades sigmóides
Tal como na regra delta, é necessário derivar uma forma de calcular o gradiente do erro, para actualizar os pesos W em cada passo. Para a unidade sigmóide o gradiente do erro é calculado da seguinte forma:
Mas sabe-se que:
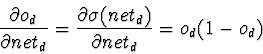
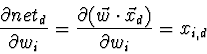
Então ficamos com: 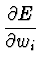
| = | 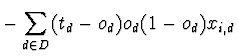
| |
e finalmente temos para actualizar W que:
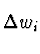 = = 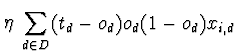
O Algoritmo deRetropropagação do Erro (backpropagation) é o método usado para aprender os pesos de uma rede multi-camadas. Este método, tal como a regra delta, aplica a descida do gradiente para minimizar o erro quadrático entre os valores de saída da rede e os valores objectivo e correctos para estes valores de saída. Como agora poderão existir várias unidades de saída há que considerar o erro E sobre todas as unidades de saída:
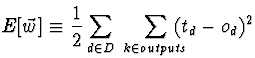
O algoritmo de retropropagação do erro apresenta-se seguidamente:
RETROPROPAGAÇÃO-DO-ERRO( exemplos_de_treino, 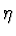 , nentrada, nsaída, nescondidos) , nentrada, nsaída, nescondidos) Cada exemplo de treino é uma par do tipo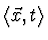 , onde , onde 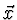 é o vector de valores de entrada, e t é o valor objectivo da saída. é a taxa de aprendizagem (ex.: .05).nentradas é o número de entradas da rede, nsaídas é o número de saídas da rede e nescondidos é o número de unidades na camada escondida. A entrada da unidade i vindo da unidade j é representado por xi,j e o peso que da unidade dessa entrada é denominado por wi,j é o vector de valores de entrada, e t é o valor objectivo da saída. é a taxa de aprendizagem (ex.: .05).nentradas é o número de entradas da rede, nsaídas é o número de saídas da rede e nescondidos é o número de unidades na camada escondida. A entrada da unidade i vindo da unidade j é representado por xi,j e o peso que da unidade dessa entrada é denominado por wi,j
- Criar a rede com nentradas entradas, nsaídas saídas e nescondidos
- Inicializar cada wi com um valor aleatório (ex. 0.05)
- Até que a condição de paragem seja encontrada, FAZER
- Para cada dos exemplos_de_treino , FAZER
- Colocar a entrada na rede e calcular a saída o, para cada unidade da rede
- Para cada unidade de saída k:
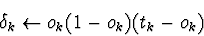
- Para cada unidade escondida h:
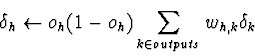
- Actualizar cada peso wi,j da rede
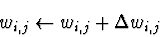
onde
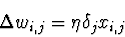
O funcionamento deste algoritmo poderá ser melhor compreendido através do seguinte exemplo dinâmico:
Relativamente a este algoritmo as principais considerações que podem ser tomadas são que:
- A descida do gradiente é aplicada sobre todo o vector de pesos da rede
- É facilmente generalizado para gráficos arbitrários direccionados.
- Encontra um erro mínimo local, que não é necessariamente o global
- Na prática, funciona frequentemente bem (algoritmo pode ser chamado várias vezes)
- Treinar várias redes com valores iniciais diferentes para os pesos
- Normalmente inclui o momentum
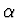 do peso: do peso:
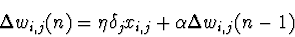
- Minimiza o erro sobre os exemplos de treino
- Será que generaliza bem para instancias futuras desconhecidas (problema do over-fitting)?
- O treino poder-se-á tornar muito lento para casos com mais de 1000 iterações.
- Usar o método de Levenberg-Marquardt em vez da descida do gradiente.
- Natureza da convergência
- Inicializar o vector de pesos com valores perto de zero.
- Rede inicial praticamente linear no início.
- Não linearidade da rede aumenta à medida que o processo de treino avança
- Utilizar a rede depois de treinada é muito rápido
Resumindo, as capacidades expressivas das RNs são:
Funções Lógicas
- Qualquer função lógica pode ser representada por uma rede com apenas uma camada escondida.
- Poderá, no entanto, necessitar de ter um número de unidades escondidas de ordem exponencial em relação às entradas.
Funções Contínuas
- Qualquer função contínua limitada pode ser aproximada com erro arbitrário e reduzido, por uma rede com uma camada escondida [Cybenko 1989; Hornik et al. 1989]
- Qualquer função pode ser aproximada até uma exactidão arbitrária, por uma rede neuronal com duas camadas escondidas. [Cybenko 1988].
Na seguinte animação apresenta-se a aplicação das RNs em bioinformática.
Neste exemplo é usada uma RN para previsão de uma determinada doença. Como base de classificação, são usados os níveis de expressões de determinados genes que se verificam numa experiência (que avalia sobre a doença). Nos exemplos de treino, o nível da doença é lido directamente na pessoa. Nas instâncias a classificar, o objectivo é saber o nível da doença previsto. Ou seja a pessoa pode ainda não estar doente, mas através da expressão de determinadoes genes, pode ser possivel dizer se algum dia sofrerá de tal doença.
|