|
A análise por agrupamento (clustering) é uma ferramenta fundamental e importante na análise estatística de informação. No passado técnicas de agrupamento têm sido amplamente usadas em numerosas áreas cientificas, como reconhecimento de padrões, recuperação de informação, análise microbiológica e outras.
Um grupo (cluster) é um conjunto de objectos de informação onde cada objecto é:
- Semelhante entre outro objecto do mesmo grupo.
- Não semelhante entre outro objectos de um grupo diferente.
O método de agrupamento baseia-se em agrupar um conjunto de informação em diferentes grupos. O número total de grupos é usualmente predefinido e cada grupo é representado por uma classe diferente. O problema de encontrar o número adequado de grupos foca a procura da complexidade correcta do modelo, dado a informação conhecida.
Este método de classificação não é supervisionado, ou seja não existem classes predefinidas.
Como aplicações típicas, este método pode ser utilizado como:
- Ferramenta individual: para recolher introspecções sobre a distribuição da informação.
- Passo do processamento: como complemento a outros algoritmos.
A figura 1 apresenta um exemplo da aplicação do método de agrupamento. Neste exemplo é feita a classificação de genes tendo em conta três condições.
Condições possíves são por exemplo:
- a percentagem de uma dada base azotada ou sequência de bases, existentes no gene
- quanto esse gene difere de um dado gene de referência (útil para descobrir potenciais doenças).
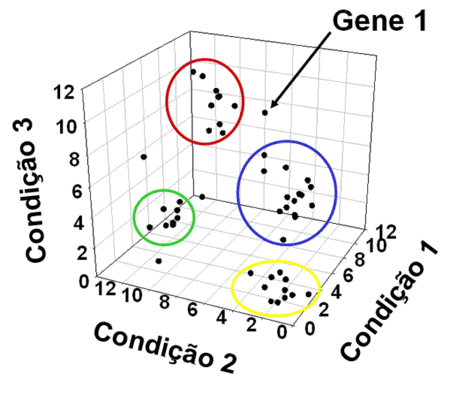
Fig. 1: Classificação de genes por agrupamento usando três condições diferentes (3-Dimensões)
Existem várias técnicas de agrupamento, nomeadamente:
Baseado em Partição:
- Construir uma partição de um base de dados D, com n objectos em k grupos.
- Dado um k, encontrar uma partição de k grupos que optimiza o critério de partição escolhido. Pode ser usado:
- Procura por óptimo global: exige enumerar todas as partições o que torna o processo exaustivo
- Métodos Heuristicos: algoritmos k-médias e k-medianas
- k-médias (MacQueen '67): cada grupo é representado pela centro do grupo.
- k-medianas (Kaufman & Rousseeuw87): cada grupo é representado por um objecto do grupo
Baseado em Hierárquica:
- Criar decomposição hierárquica da informação
Baseado em Modelo:
- Modelo é colocado em hipótese para cada grupo
- Encontrar modelos que melhor se ajustam à informação e entre eles
|
