|
O K-médias é um algoritmo de agrupamento iterativo que:
- Classifica objectos num determinado número prédefinido K de grupos (clusters).
- Tem como função de classificação a distância do objecto ao centro do grupo (centróide).
- Minimiza a soma J de todas as distâncias euclidianas entre cada objecto e o seu centróide, segundo o critério dos mínimos quadrados dado por:
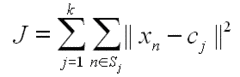
O algoritmo pode ser descrito na seguinte forma, onde os três passos mais importantes encontram-se enumerados entre parênteses:
K-MÉDIAS( exemplos_de_treino, k) Cada exemplo de treino é um vector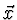 de dimensão N, com os valores de cada condição. k é o número de grupos/centróides a usar no algoritmo. de dimensão N, com os valores de cada condição. k é o número de grupos/centróides a usar no algoritmo.
- (1) Escolher k centróides aleatoriamente (ex.: k pontos escolhidos aleatoriamente dos exemplos_de_treino)
- Enquanto os centróides são modificados , FAZER
- Para cada centróide c, FAZER
- (2) Actualizar o centróide com a média dos pontos que lhe pertence, ou seja, que pertencem ao seu grupo.
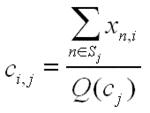
onde :
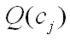 é o número de objectos que pertence ao grupo cj é o número de objectos que pertence ao grupo cj
ci,j é a dimensão i do centróide j, para i = {1,...n}, j = {1,...k}
xn,i é a dimensão i do exemplo_de_treino xn. xn pertencente ao centróide j, para i = {1,...n}, j = {1,...k}
- Para cada exemplo_de_treino d, FAZER
- (3) Atribuir o centróide c que se encontra mais perto de d.
A figura 1 ajuda a compreender o funcionamento deste algoritmo.
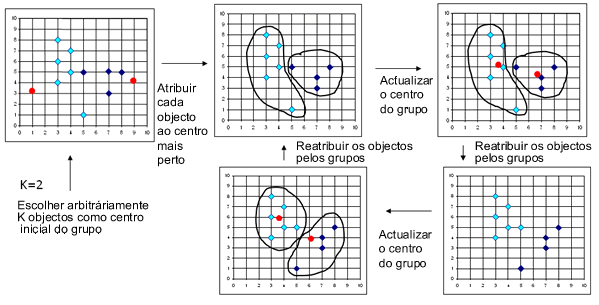
Fig. 1: Passos de aplicação do algoritmo K-médias
Apresenta-se de seguida um exemplo dinâmico deste método de agrupamento:
NOTA: Caso não surja nenhuma animação em cima, será necessário proceder à instalação do programa Macromedia Flash Player, aqui. A instalação permitirá visionar este tipo de conteúdos FLASH correctamente.
Na animação que se segue, pode ser visualizada uma aplicação do agrupamento (e deste algoritmo) na bioinformática. O agrupamento é feito recorrendo ao uso de microarrays para representar a expressão de genes.
O algoritmo K-médias apresenta como vantagens:
- Todos os objectos de informação são automaticamente atribuídos a um grupo
- A localização inicial do contróide do grupo pode variar, o que permite estabelecer condições iniciais de dependência.
No entanto as desvantagens são que:
- Antes do algoritmo ser iniciado tem de ser escolhido o número de grupos.
- Todos os objectos de informação são forçados a pertencer a um grupo.
|
